Abstract
By: Rajat Ghosh, Staff Data Scientist, Arijit Hawlader, Sr. Product Manager, Charan Shampur, Staff Engineer, Kashi MN, Staff Engineer, Jinan Zhou, Member of Technical Staff 3, Nitin Mehra, Director - SaaS Engineering, Pramod Vadiraj, Senior Manager - SaaS Engineering, Manoj Thirutheri, Vice President - SaaS Engineering, and Debojyoti Dutta, VP, Engineering
Abstract
At Nutanix we are validating the effectiveness of Retrieval Augmented Generation (RAG) for potential use within the internal Slack® OneNutanix workspace, functions as a Question-Answering bot designed for customer support purposes and has successfully concluded its proof-of-concept phase. The underlying architecture employs the RAG pipeline, with Milvus serving as the vector database and a fine-tuned LLaMA-2-13b for Language Model Matching (LLM).
This document presents a comprehensive overview of the experimental development of the RAG pipeline. Following established norms of AI/ML product development, the process has unfolded iteratively over an eleven-week period, involving experimentation with diverse modeling techniques and parameters. Evaluation criteria encompassed accuracy, precision, recall, and the system's proficiency in rejecting the harmful content generation.
Introduction
Introduction
Customer support is an integral aspect ingrained in our organizational ethos, and the Nutanix Support ecosystem empowers us to deliver top-tier services to our clientele. The advent of Generative AI tools presents an auspicious opportunity to revolutionize our support delivery methodology. This transformation encompasses enhancements in both self-service capabilities and Systems Reliability Engineering (SRE) productivity, thereby fostering a positive impact on our Net Promoter Score (NPS) and support cost dynamics.
A fundamental technical challenge lies in the current initial reliance on a page-rank algorithm for search functionality at Nutanix. This approach poses difficulties for service reliability engineers and customers in obtaining highly contextual answers essential for issue resolution. We posit that this challenge can be effectively addressed through the implementation of a Language Model (LLM)-based question-answering interface. This interface, anchored in a foundational model like LLaMA-2 and fine-tuned using specific Nutanix data, aims to provide nuanced, contextually rich, and precise responses to user queries, thereby enhancing the overall support experience.
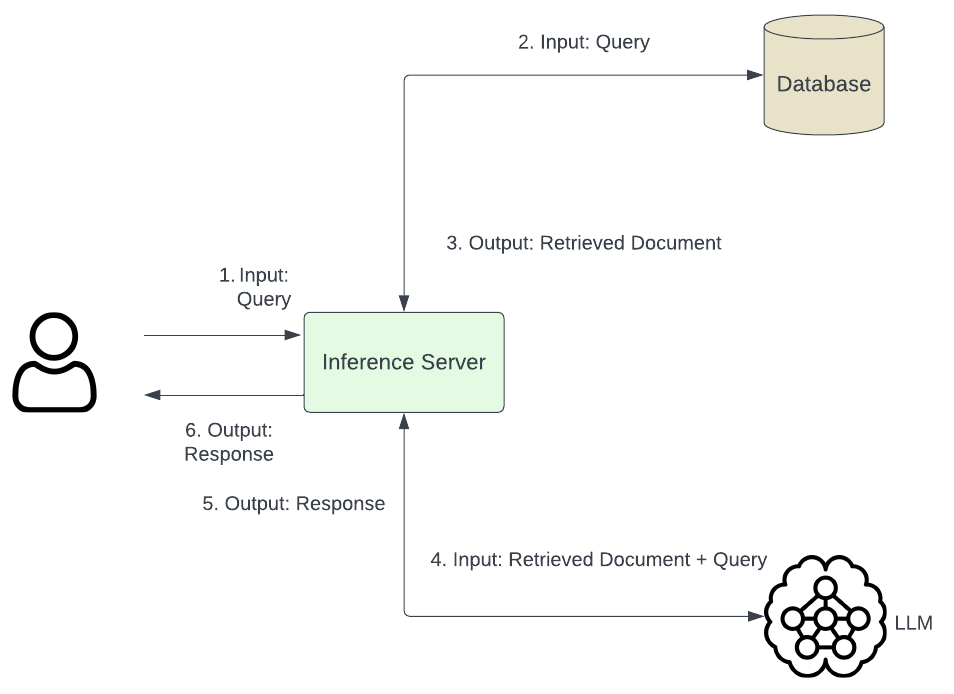
Figure 1: Technical Architecture of RAG
As depicted in Figure 1, the technical architecture of RAG delineates the information flow, which can be elucidated through the following sequential steps:
- User Query Submission: A user initiates the process by submitting a query to the system.
- Inference Server Processing: The inference server undertakes the processing of the user query and subsequently transmits it to the designated database.
- Document Retrieval: The database retrieves pertinent documents based on the processed query and forwards them back to the inference server.
- Query-Document Fusion: The inference server integrates the original user query with the retrieved documents, forming a composite input.
- Language Model Processing: The composite input is then conveyed to the Language Model (LLM), which generates a response based on the integrated information.The LLM-generated response is transmitted back to the inference server.
- User Response Delivery: The inference server delivers the finalized response to the user, thereby completing the information flow cycle.
We are using RAG to retrieve data from outside a foundation model and augment prompts by adding the relevant retrieved data in context. Here are the tools we have used for this project:
- Vector Database: Milvus
- Embedding Model: sentence-transformers/all-MiniLM-L6-v2
- LLM: Llama-2-13B
- Fine Tuning: PEFT/LoRA
During this POC phase, we have indexed nearly 2,000 Nutanix support portal knowledge bases (KB). All of these KBs have a specific schema with following fields such as <Title, Summary, Description, Solution, Internal Comments>.
To bring enterprise value, a large language model (LLM) needs to be tailored with a specific dataset suitable for a particular use case, such as question-answering, code-generation, image-generation, and many more. LLMs based on the transformer architecture, like GPT, T5, and BERT, have achieved state-of-the-art (SOTA) results in various Natural Language Processing (NLP) tasks especially for text generation and conversational bots. The conventional paradigm is large-scale pretraining on generic web-scale data (CommonCrawl), followed by fine-tuning to downstream tasks. LLM models store their learnings in their weights. Fine-tuning modifies these model weights to adapt to a downstream task, however for a knowledge-intensive task such adaptation is often insufficient. This is where the ability of having the differentiable access to an explicit non-parametric memory brings significant value. Retrieval-augmented generation (RAG) systemizes this combination of explicit access to the non-parametric memory with the parametric memory captured in the LLM weights.
Development Process
Development Process and Experimentation
Following the initial deployment, we conducted multiple iterations on the RAG optimization process. This involved exploring various Language Model Models (LLMs), experimenting with the data pipeline, and engaging in prompt engineering, as outlined in Table 1. We evaluated the performance of the Falcon 7B, Llama-2-7B, and Llama-2-13B models. In the data pipelining phase, we experimented with adjustments to context fields, HTML character cleansing, and the removal of special characters. Notably, prompt engineering proved to be particularly challenging, as many models and orchestration tools, including LangChain, exhibited a high sensitivity to prompt style and content. Ultimately, we settled on the following prompt for optimal results:
prompt_template: str = \
"""
Please answer the query strictly based on the given context.
Context: {context}
Query: {query}
Answer:
"""
We have also noticed that the LangChain wrapper function degrades the robustness on our limited test runs.
Table 1: Iterative Improvement of RAG Quality Improvement
During these iterations, we measure the output quality based on the three metrics:
- Accuracy: Accuracy measures whether the LLM can generate answers precisely. A high accuracy means fewer hallucinations. Also, it means that the right documents have been retrieved. Our best RAG pipeline (Test 9) has reached a 78.60% accuracy score with simple and medium complexity questions. The evolution of accuracy improvement is shown in Figure 2.
- Completeness: Completeness measures whether the LLM can generate answers without missing pertinent details. A high completeness means LLM can combine the fetched documents effectively to produce a thorough answer. Our best RAG pipeline (Test 9) has reached a 77% completeness score. The evolution of completeness improvement is shown in Figure 3.
- Safety: Safety metric measures the absence of offensive response generation from the RAG pipeline. Our best RAG pipeline (Test 9) has reached a 100% safety score. The evolution of safety improvement is shown in Figure 3. The safety benchmarking was performed using the OpenAI Safety questionnaire.
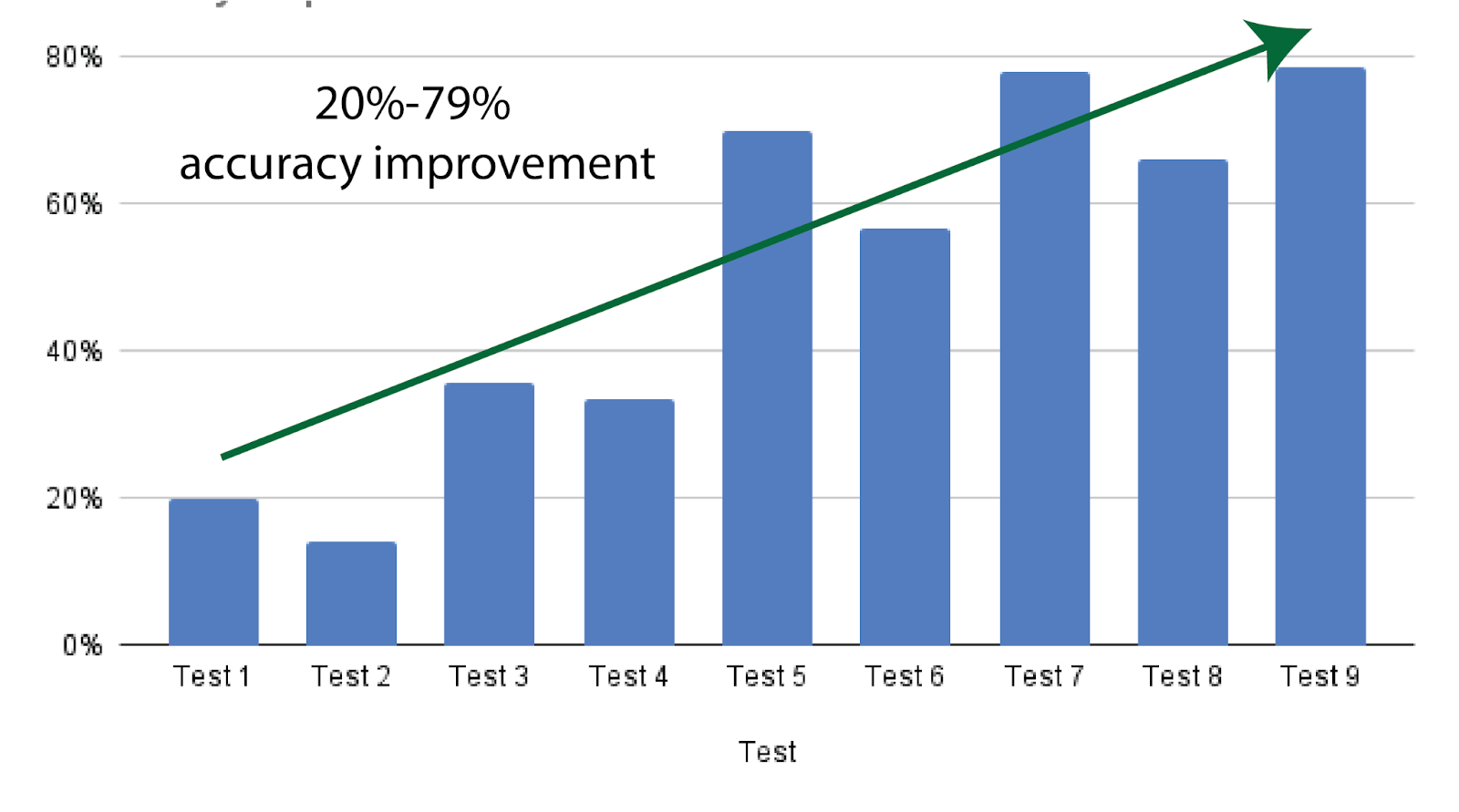
Figure 2: This Figure shows the iterative improvement of the accuracy of the RAG pipeline from 20% in Test 1 to 78.60% in Test 9.
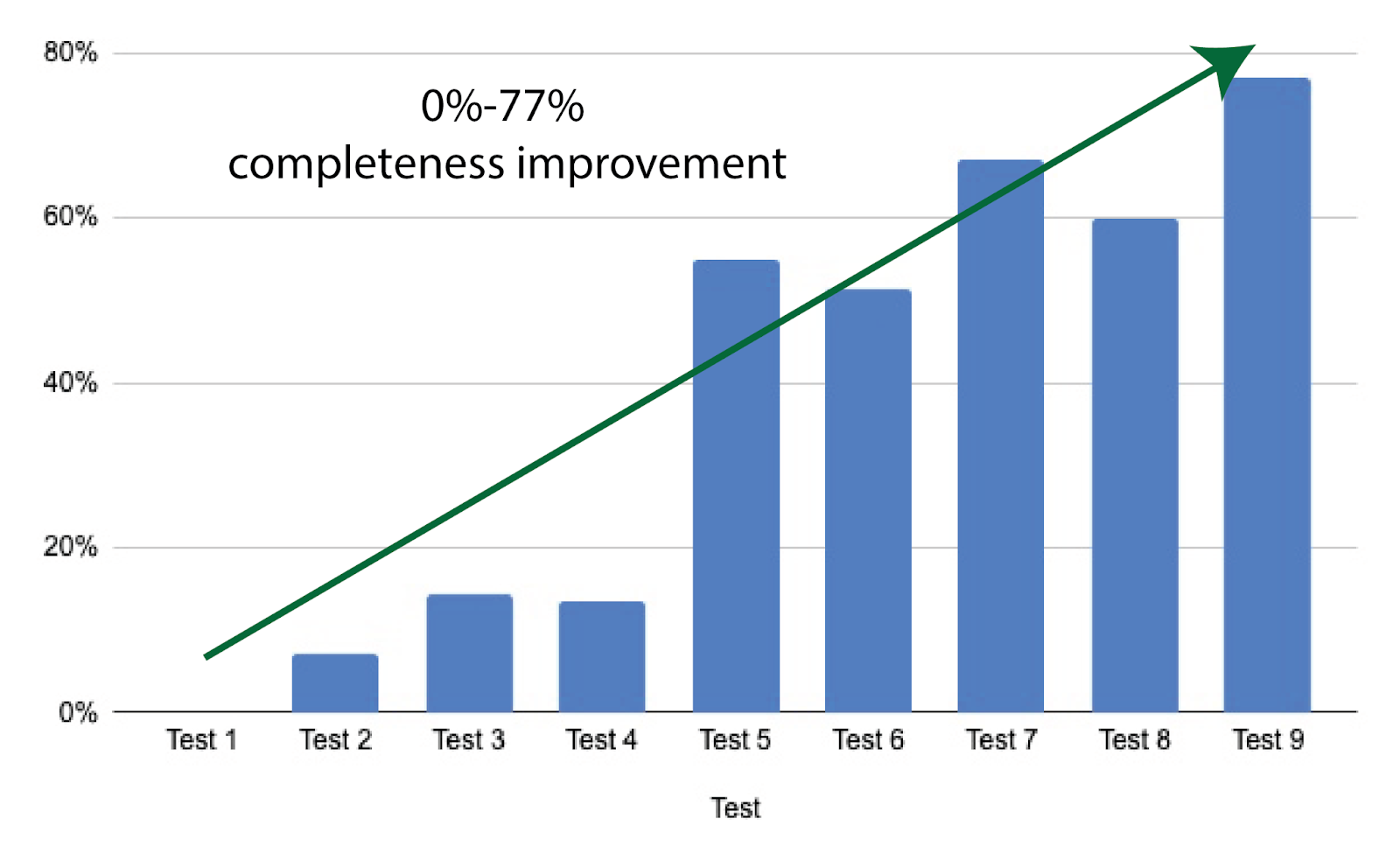
Figure 3: This Figure shows the iterative improvement in the completeness of the RAG pipeline from 0% in Test 1 to 77% in Test 9.

Figure 4: This Figure shows the iterative improvement in the safety of the RAG pipeline. It shows the safety of the RAG pipeline remains around 100% throughout. It means we never compromise on safety measures.
From the ML standpoint, it is non-trivial to improve accuracy and completeness concurrently. All these tests were based on a test dataset with three fields {Question, KB, Response} tuples and there was only one single human evaluation. The number of test questions changes over the different tests shown in Figure 5..

Figure 5: This Figure shows the number of test questions that have been used to evaluate the RAG pipeline.
Results
Results
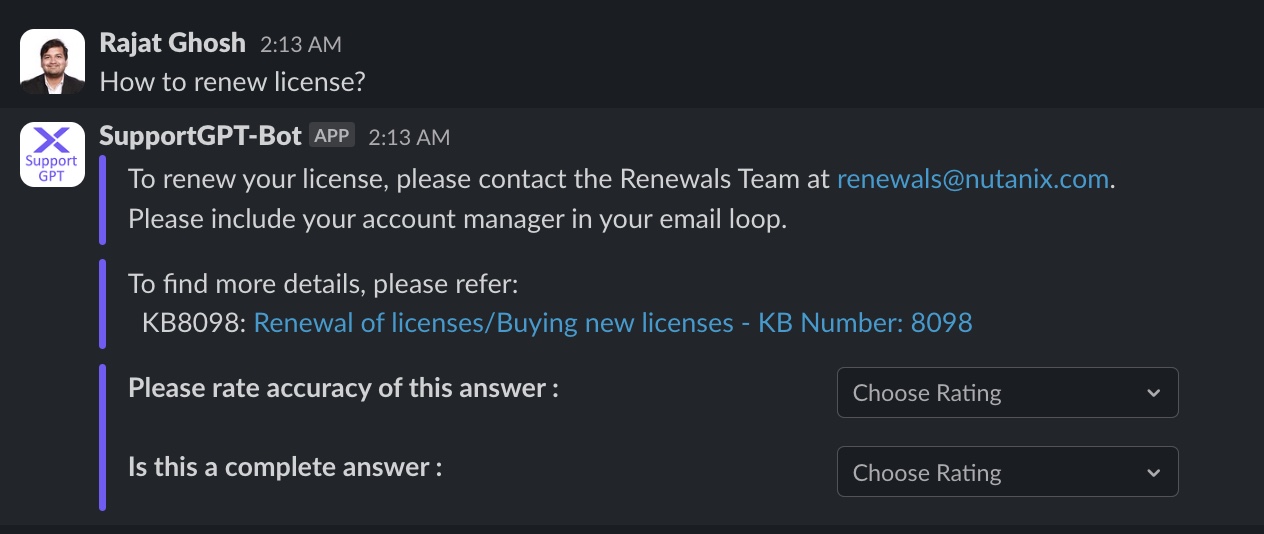
The experimental RAG app runs as a Slack® app with the user interface shown in Figure 6. It has four different sections: Question, LLM generated response, retrieved document, and user feedback section on accuracy and completeness.
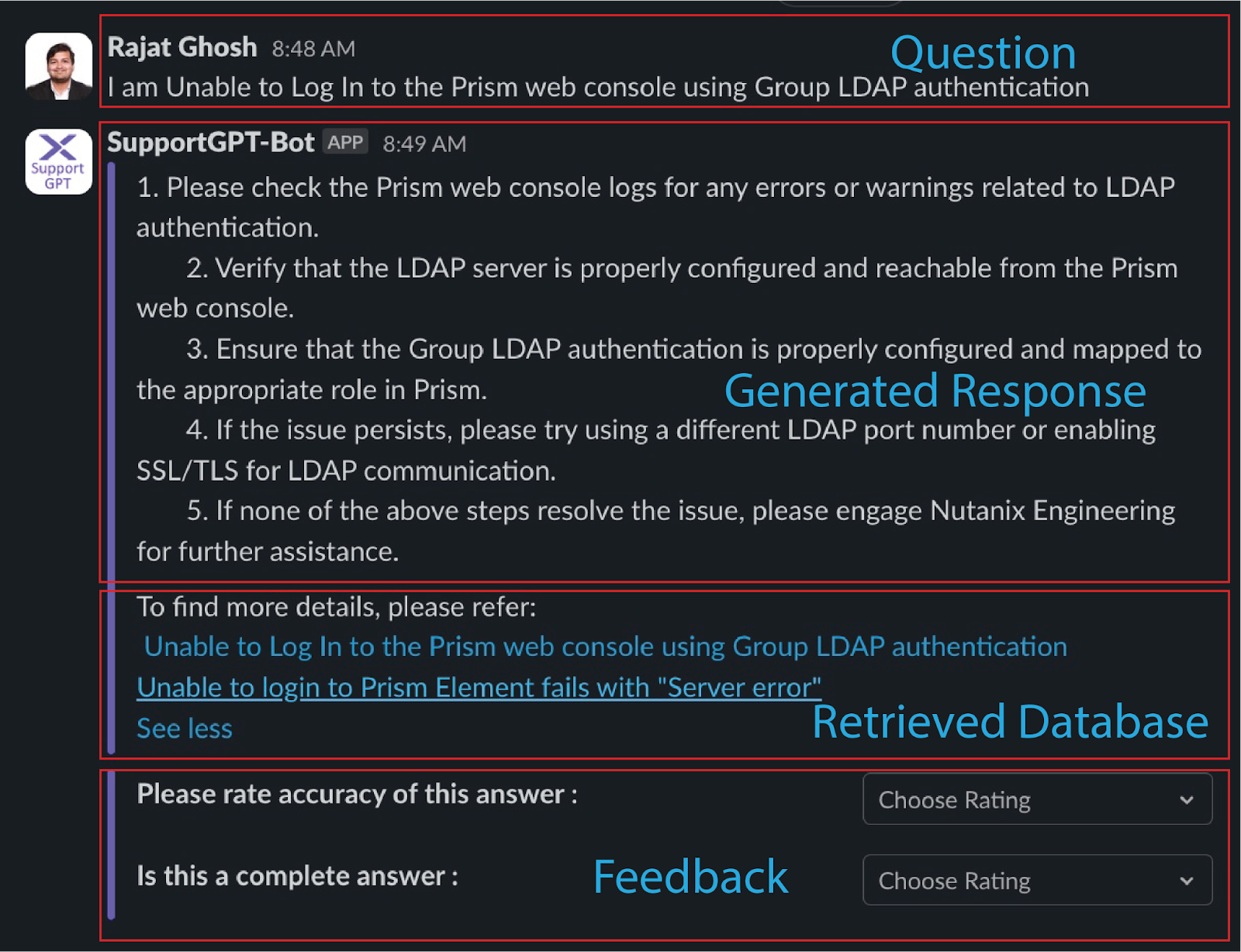
Figure 6: The canonical UI for the RAG pipeline.
Out of 40 test {Question, Document, Response} tuples, our best RAG pipeline has reached 78% accuracy and 67% completeness.
Question 1
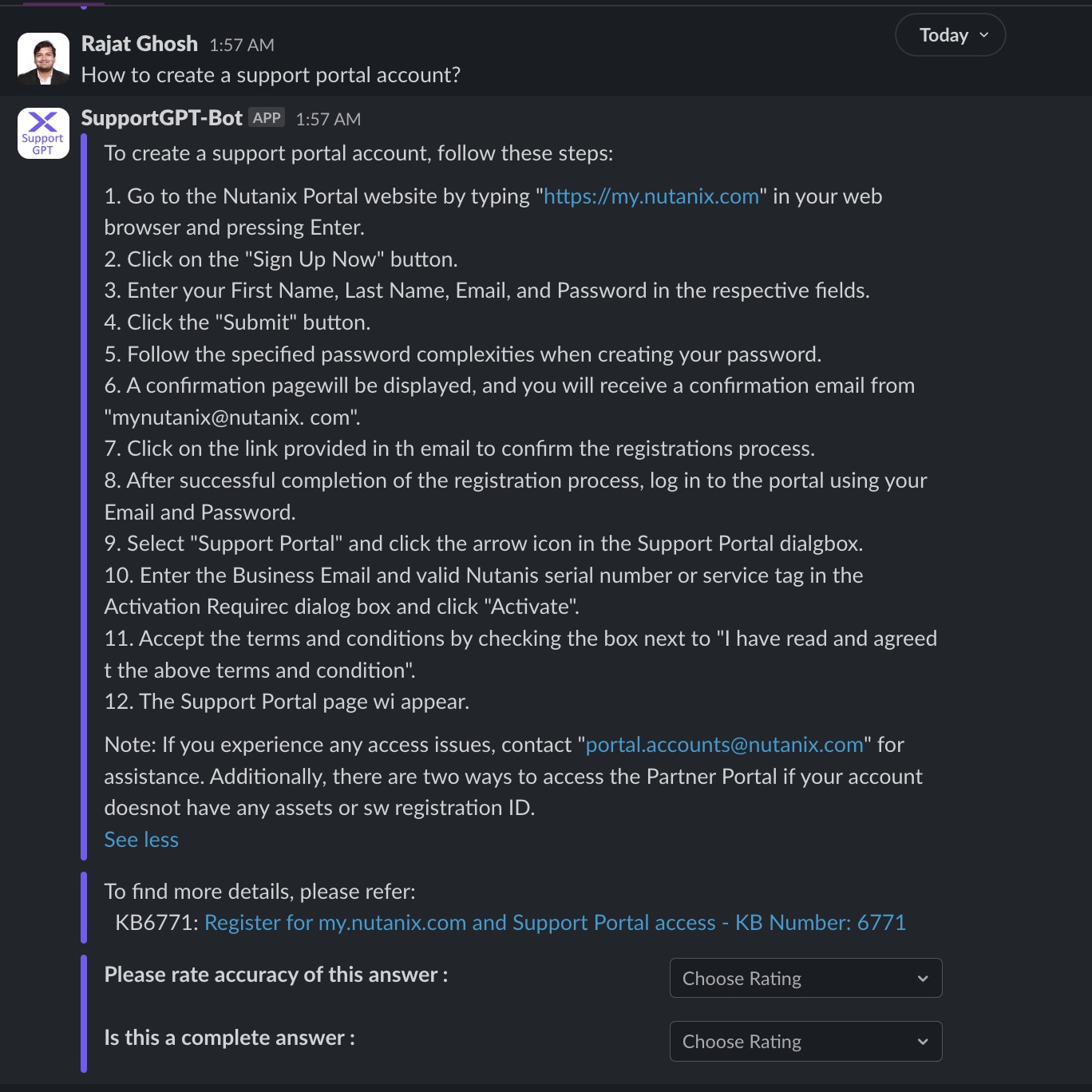
Question 2
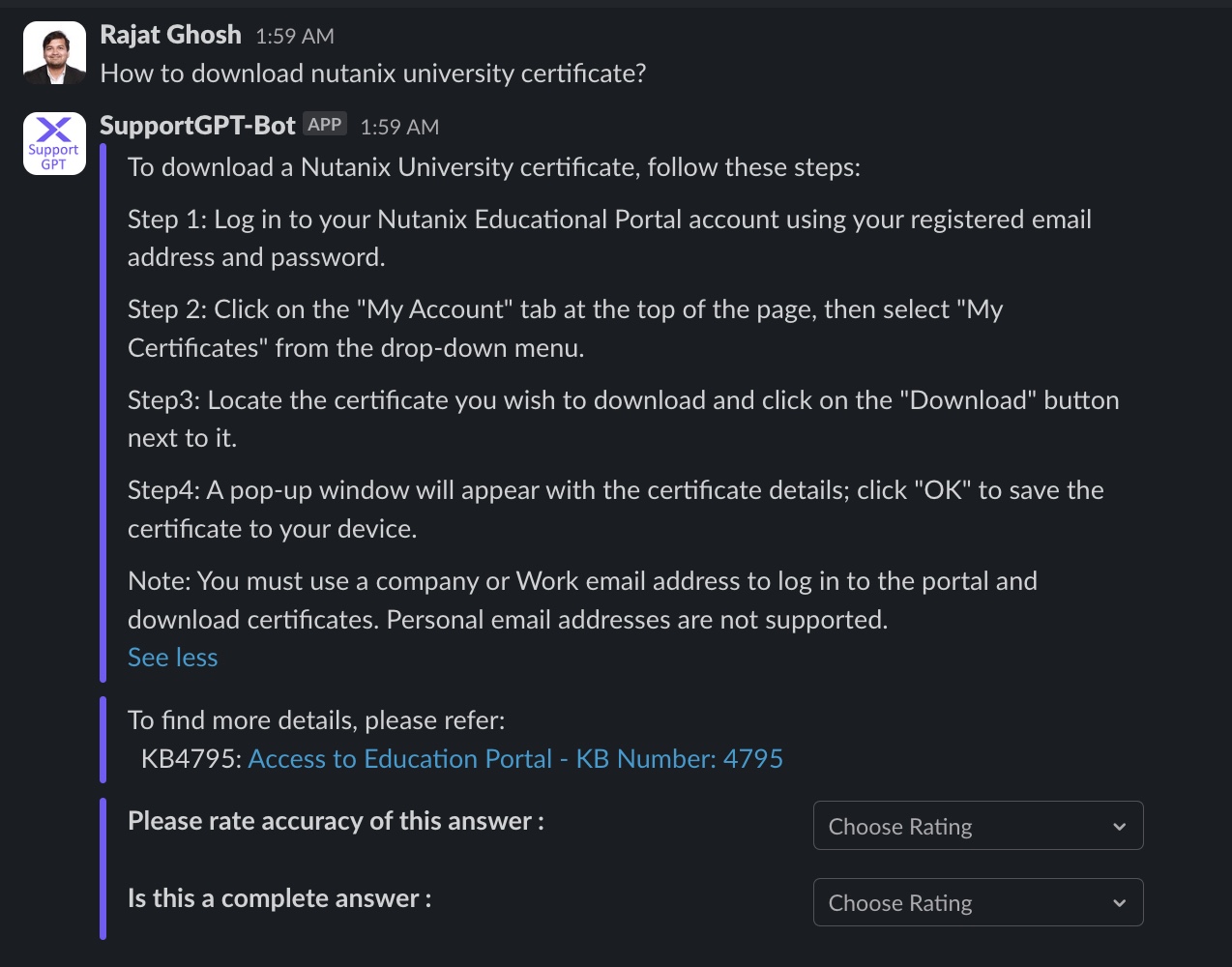
Question 3
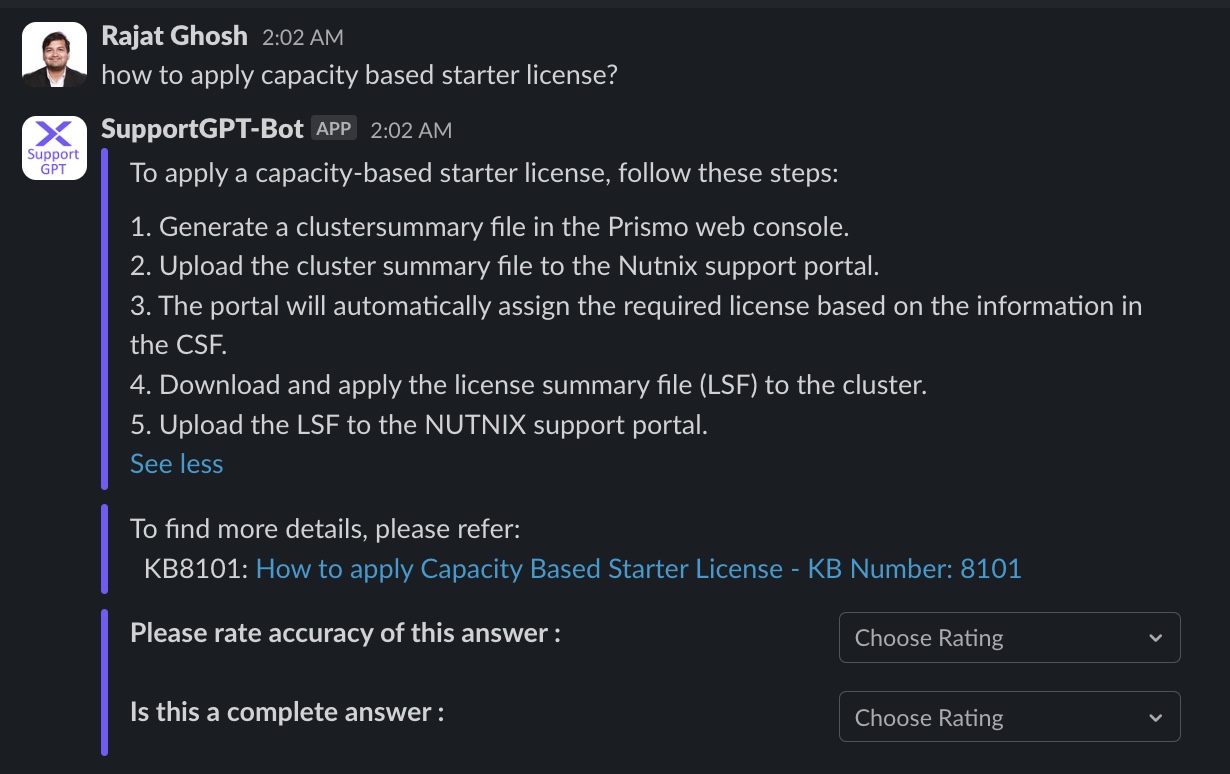
Question 4
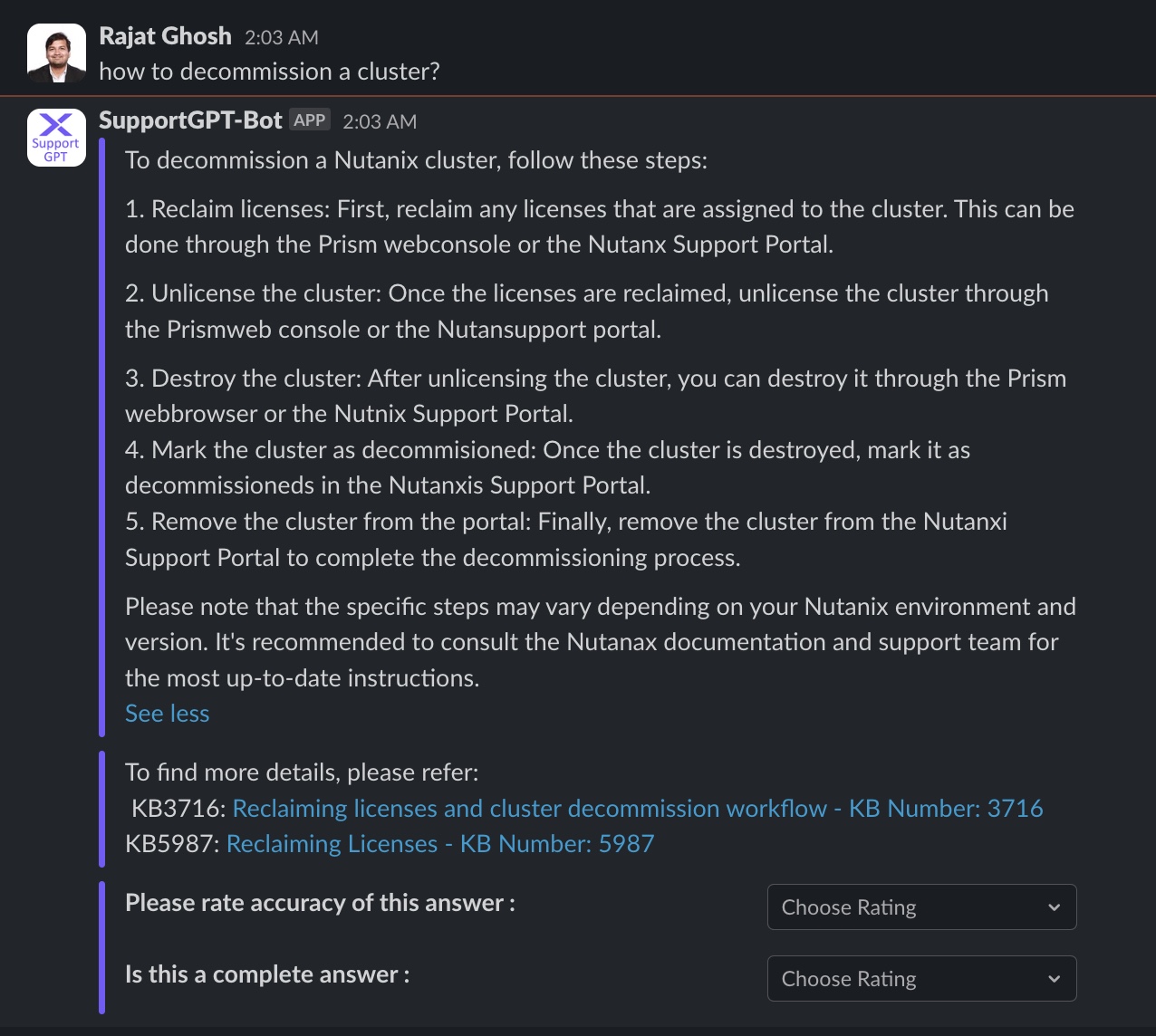
Question 5
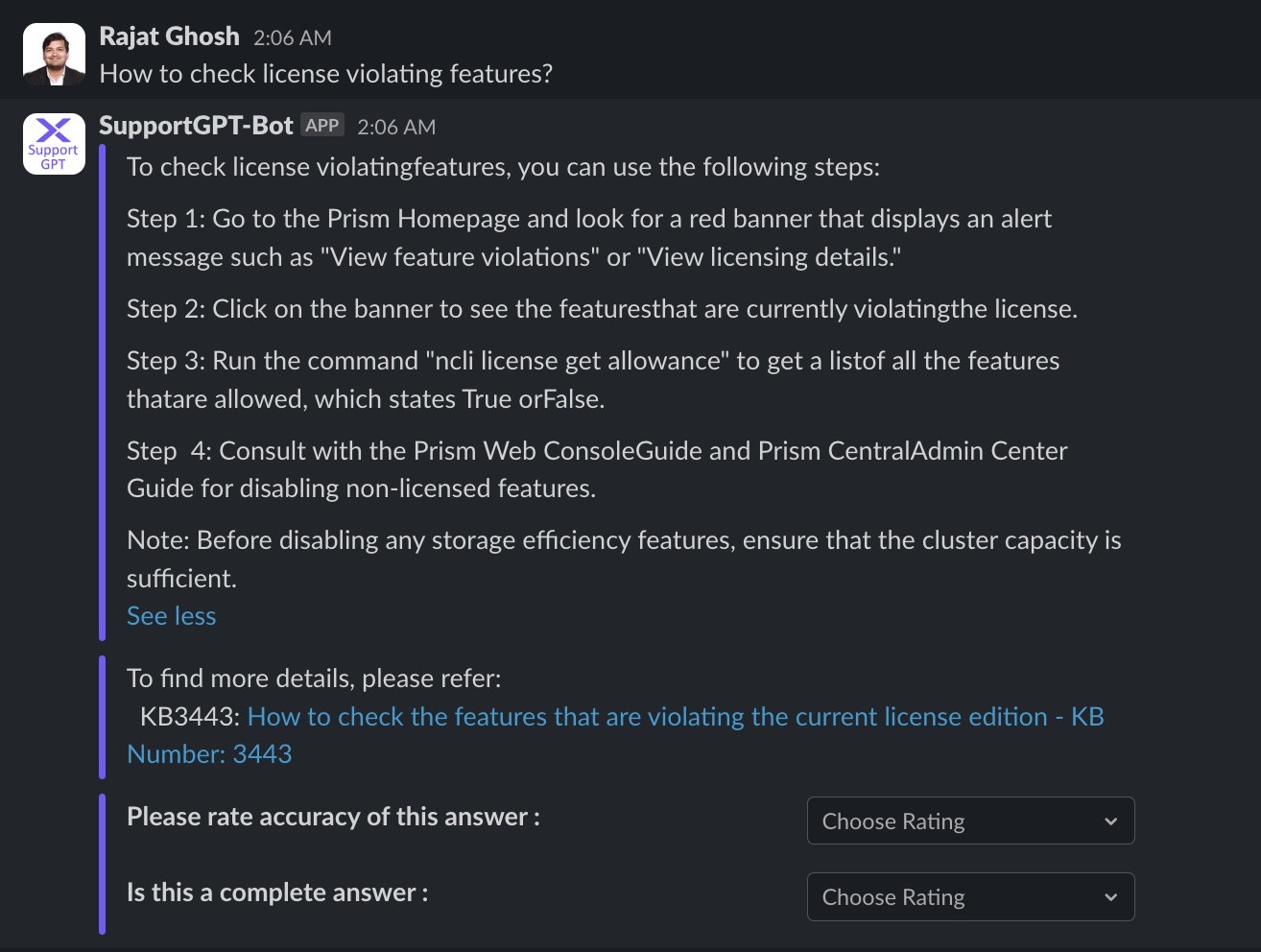
Question 6
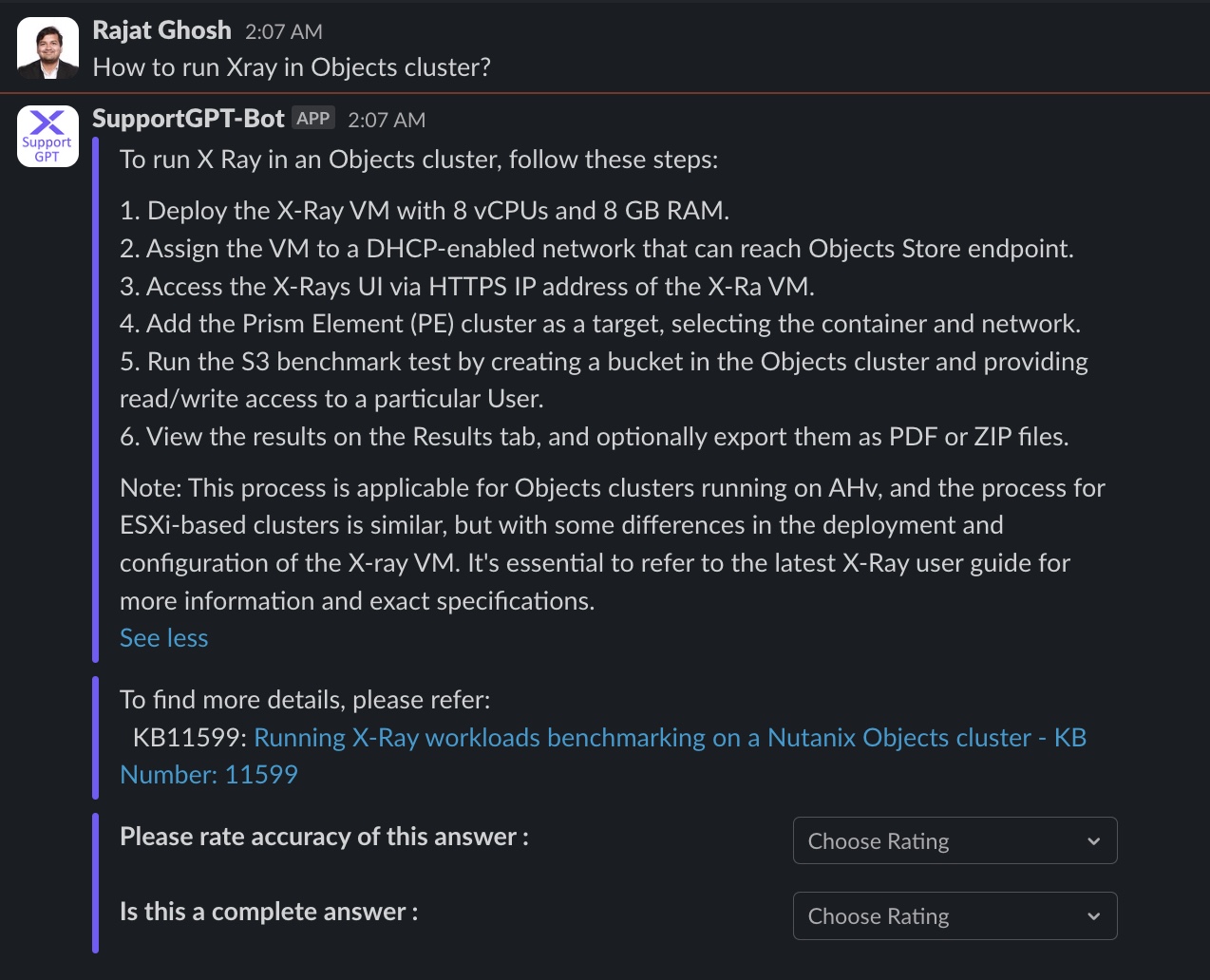
Question 7
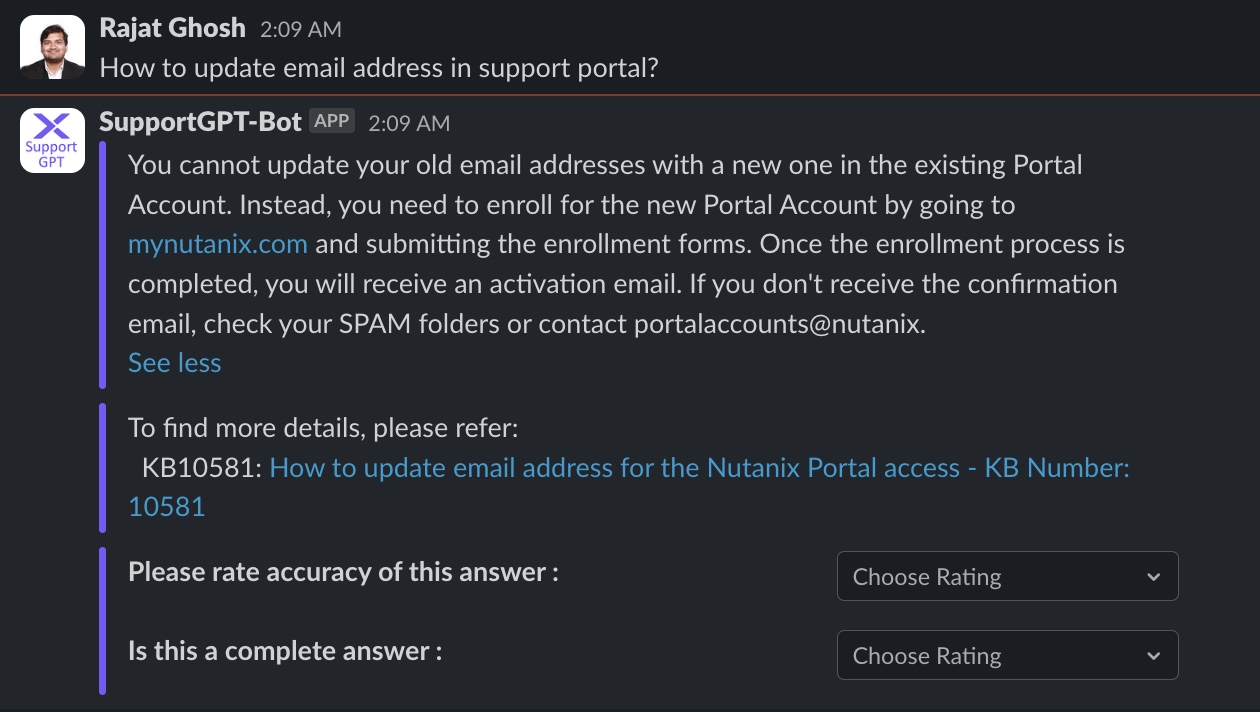
Question 8
Question 9
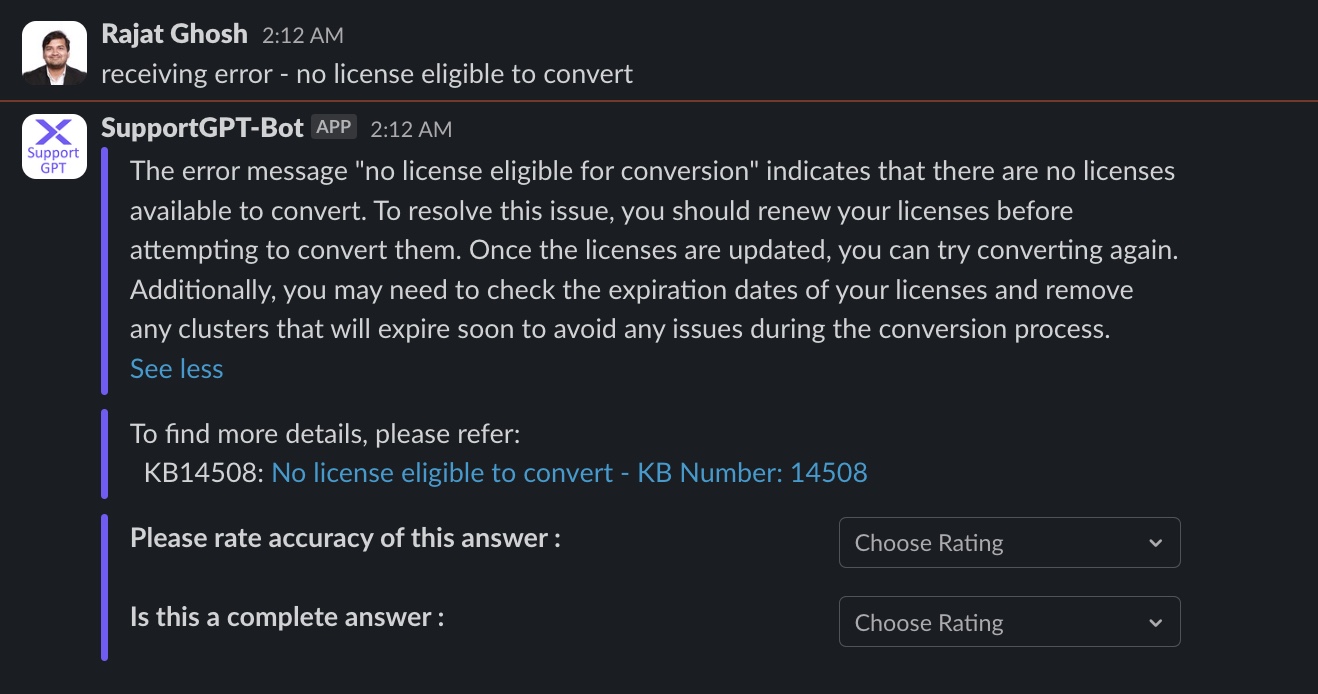
Question 10
Best Practices
Best Practices
While we cannot claim any generalizability, we have indeed observed a few performance patterns during our experimentations with the RAG pipeline. From those patterns, we can offer the following best practices for similar RAG projects with a hybrid dataset including html pages with code snippets, html tables, and raw texts.
- Data Sanitization
- Get rid of special html tabs
- Make sure there is no unnecessary empty spaces
- Model Quality
- Choose high-quality fully-vetted models
- Often downloading models and running it from local repositories works better than third-party curated libraries.
- Prompt Engineering
- LLM outputs from smaller models (<40B parameters) are very sensitive to prompts both in terms of content and form. It is advisable to experiment with a large cohort of potential prompts.
Summary
Summary
Several noteworthy accomplishments of the RAG project thus far encompass:
- Establishment of a comprehensive end-to-end Retrieval-Augmented Generation (RAG) pipeline, incorporating the Milvus vector database, sentence-transformer-based embedding, and Llama-2-13B for Large Language Model (LLM) functionality.
- Thorough model optimization endeavors have been undertaken to enhance pipeline accuracy to 78% and completeness to 67%.
- Presently, our focus is on meticulous model testing and fine-tuning of hyperparameters.
© 2024 Nutanix, Inc. All rights reserved. Nutanix, the Nutanix logo and all Nutanix product, feature and service names mentioned herein are registered trademarks or trademarks of Nutanix, Inc. in the United States and other countries. Other brand names mentioned herein are for identification purposes only and may be the trademarks of their respective holder(s). This post may contain links to external websites that are not part of Nutanix.com. Nutanix does not control these sites and disclaims all responsibility for the content or accuracy of any external site. Our decision to link to an external site should not be considered an endorsement of any content on such a site. Certain information contained in this post may relate to or be based on studies, publications, surveys and other data obtained from third-party sources and our own internal estimates and research. While we believe these third-party studies, publications, surveys and other data are reliable as of the date of this post, they have not independently verified, and we make no representation as to the adequacy, fairness, accuracy, or completeness of any information obtained from third-party sources.